
Les termes « Libérez vos données » ou « Une nouvelle vision des données » vous disent-ils quelque chose ?
Ce sont des expressions couramment employées par les fournisseurs d’infrastructures de stockage dans le but de simplifier ce processus complexe qui consiste à stocker des données et à les rendre accessibles aux utilisateurs et aux processus qui en ont besoin.
En fin de compte, vos données représentent véritablement toute votre activité. Disposer des bonnes données au bon moment aide les gens à prendre des décisions plus intelligentes et plus éclairées concernant leur entreprise.
Par conséquent, disposer de la bonne infrastructure de stockage, celle qui facilite la livraison des données à la personne ou au processus qui en a besoin de la manière la plus rationnelle et la plus économique, est également un élément essentiel pour que de meilleures décisions commerciales soient prises.
Alors, pourquoi est-il si difficile de déterminer le type de stockage dont vous avez besoin ?
Comment déterminer le stockage dont vous avez besoin ? Cet article donne une vue d’ensemble de chaque technologie de stockage (bloc, fichier et objet) et décrit le rôle joué par chaque type de stockage pour influencer les décisions métier. Après tout, les organisations d’aujourd’hui peuvent disposer d’interfaces fichier sur le stockage objet et d’interfaces objet sur le stockage fichier. Comprendre la fonction de départ de chacune de ces méthodes de stockage vous aidera donc à évaluer les technologies de stockage et à voir en quoi elles peuvent être adaptées à vos besoins métier spécifiques.
D’un point de vue technique, la prise de meilleures décisions pour l’entreprise commence par l’architecture de stockage sous-jacente et par l’interface externe.
Le stockage bloc est structurant
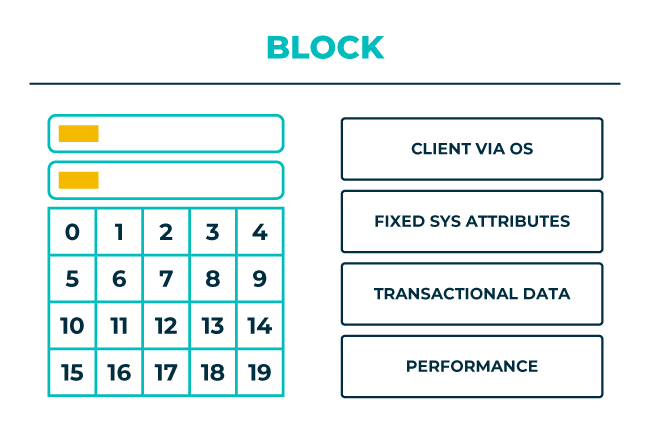
La base de tous les types de stockage externes est le stockage bloc. Avec ce type de stockage, les données sont stockées sous forme d’octets (8 bits) et organisées en segments ayant chacun sa propre adresse.
Vue de l’extérieur, c’est la forme de stockage la plus brute, un peu comme une ardoise vierge pour des logiciels système tels que les bases de données et les systèmes d’exploitation. Le bloc de données sert d’abstraction pour ce qui se passe au-dessus de lui. Le sous-système connaît l’adresse des blocs (segments de données) et peut mettre à jour des blocs spécifiques.
Les logiciels et autres structures de données telles que les fichiers sont constitués de milliers de blocs. Puisque le stockage bloc peut mettre à jour les segments de façon très fine, il est idéal pour les environnements nécessitant une faible latence et exécutant de nombreuses transactions. Si quoi que ce soit change, il vous suffit de mettre à jour quelques blocs et non la totalité des données.
Qu’est-ce que le stockage bloc ?
Pour le stockage bloc, la haute disponibilité et les performances sont deux caractéristiques essentielles. Pour les décisions métier, le stockage bloc est un socle permettant de prendre en charge les applications stratégiques et commerciales de manière fiable, rapide et efficace.
Le stockage fichier facilite la collaboration
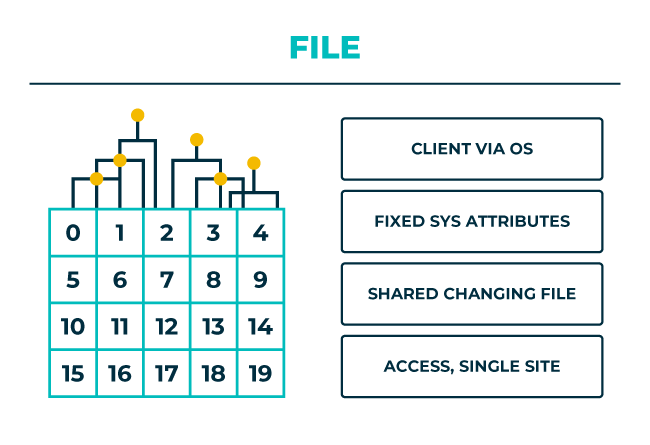
Le stockage fichier est rendu possible par un système de fichiers, c’est-à-dire une structure de données installée au-dessus du stockage bloc, qui stocke les données dans des répertoires, des sous-répertoires et des noms de fichiers. Le système de fichiers contrôle l’accès aux fichiers et régit leur partage et leur verrouillage. Il gère en outre tous les attributs des fichiers (tels que la création, la modification, la date d’accès, le type et la taille). Les appareils de stockage réseau (NAS) appartiennent à la catégorie du stockage fichier et assurent le stockage sur un réseau étendu (WAN) ou un réseau local (LAN).
Qu’est-ce que le stockage fichier ?
La structure des répertoires, le nom des fichiers et la gestion de l’accès aux fichiers et des attributs sont les éléments qui autorisent la collaboration au sein de l’organisation. Vous pouvez permettre à plusieurs personnes d’accéder et de travailler sur un même fichier. Le système de fichiers gérera alors ces versions et ces mises à jour en conséquence selon ce que chaque utilisateur est autorisé à faire. Du point de vue des décisions métier, le stockage fichier aide de multiples utilisateurs à transformer les données en éléments d’information consommables tels que des documents, des images, de l’audio, de la vidéo, des graphiques, etc.
Le stockage objet permet un accès distribué sur le long terme
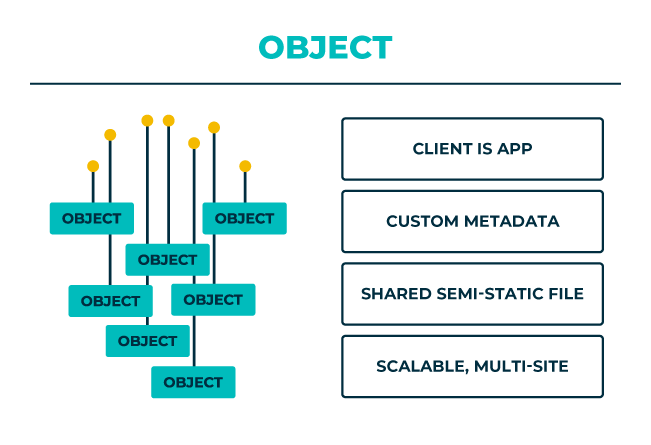
Les solutions de stockage objet stockent les données sous forme d’objets sur un disque. Chaque objet reçoit une clé unique (système également appelé stockage clé/valeur ou Content Addressable Storage). Il vous suffit de disposer de cette clé pour accéder à l’objet (données non structurées comme un document, une photo, une vidéo ou du son). Toutes les solutions de stockage objet sont accessibles via une interface RESTful sur HTTP. Autrement dit, il vous suffit d’accéder au système de stockage objet via Internet ou un réseau interne et de posséder cette clé pour accéder au contenu.
Qu’est-ce que le stockage objet ?
Le stockage objet est idéal pour les ensembles de données très volumineux. En effet, le logiciel de stockage objet peut être installé sur des serveurs peu coûteux et les données peuvent circuler librement à travers le système. Le logiciel de stockage objet peut continuer à ajouter des ressources, tout en optimisant et en équilibrant en permanence l’ensemble de la solution de stockage. Cela est en revanche difficile à réaliser avec un stockage fichier car les fichiers sont verrouillés par le chemin d’accès nom du répertoire/fichier spécifique.
C’est cette approche qui explique que le stockage objet se trouve à la base de tous les services de stockage Cloud et au cœur de tous les services qui fournissent des données non structurées (services audio, services de vidéo à la demande, services de photo, etc.). Du point de vue des décisions métier, le stockage objet aide un grand nombre d’utilisateurs finaux et d’applications à consulter et à consommer des données non structurées de manière simple, quel que soit l’emplacement des données.